

Two of my adult children are in Poland right now, spending two weeks there during the Advent season. I’m so excited for them to have this opportunity to visit the land that was home to three-quarters of their ancestors. Neither of them is especially interested in genealogy, so their tour is focused on sightseeing, and discovering a bit of the history and culture of Poland. Consequently, I have no expectation that my kids will tour the cemeteries where their ancestors were laid to rest. I’ve discovered that visiting cemeteries isn’t really the kind of thing that non-genealogists seem to enjoy, for some odd reason. (Yes, my tongue is planted firmly in my cheek as I write that.) Nonetheless, I started thinking about the most recent generation of our family who lived and died in Poland: the parents of the immigrants. Who were they, when did they live, what churches were they buried from, and in what cemeteries were they buried?
A Word About Polish Cemeteries…
Even if my kids did wish to visit our ancestral cemeteries, there wouldn’t be much to see in terms of ancestral graves, because none of those graves are still marked. Although it seems strange to us here in the U.S.—and particular so here in New England, where we have an abundance of cemeteries with grave markers that date back to the early 1700s—permanent graves are uncommon in Poland. Graves are rented out for a particular term—perhaps 25 years—and at the end of that period, the family must renew the lease in order to maintain the grave. If the cemetery fees are not paid, the grave is resold, and the grave marker is replaced with a new one. For this reason, it’s rare to find grave markers in Poland that are more than 100 years old. In fact, when we visited Poland in 2015, the only grave of a known relative that I could identify in all the ancestral cemeteries we visited, was that of Barbara (née Kalota) Mikołajewska, sister of my great-great-grandmother, Marianna (née Kalota) Zielińska. Barbara was buried in this Mikołajewski family plot, shown in Figure 1.

Despite the fact that the graves are no longer marked, most of the small, country parishes in Poland have only one Catholic cemetery. So, if a death was recorded in a particular parish, it follows that the deceased was buried in that parish cemetery. Consequently, there’s a feeling of connection for me that comes from visiting an ancestral village—and particularly its cemetery; a connection that comes from the knowledge that, in this place, my family had roots. These are the streets my ancestors walked, and the fields that they farmed. This is the church where they came to pray; where they stood before the congregation to be joined in holy matrimony, and where they brought their babies to be baptized. This is the cemetery where they were laid to rest, and where they returned to dust. This place is a part of my DNA, just as my ancestors’ DNA has become a part of this place.
But how to convey this to my non-genealogist kids? Making family history meaningful and interesting to my immediate family has always been a challenge for me, so whenever I have a family history story to tell—especially one related to a distant ancestor—my husband has always advised me to start with someone he knows.
My kids have nine great-great-grandparents who were themselves born in what is now Poland, and three more who were born in the U.S. of Polish immigrant parents. However, some of those great-great-grandparents who were born in Poland came to the U.S. with their parents. So, we have to go back several generations to uncover the 3x-, 4x-, and 5x-great-grandparents who were still living in Poland when they died. Those connections are pretty distant for non-genealogists to appreciate, so I’ll take my husband’s advice, and frame these ancestors in terms of their relationships to great-grandparents that my children knew personally, or knew from family stories.
Grandma Helen’s Family
My maternal grandmother, Helen (née Zazycki) Zielinski, died in 2015, so all my children knew her well. Her pedigree chart is shown in Figure 1.

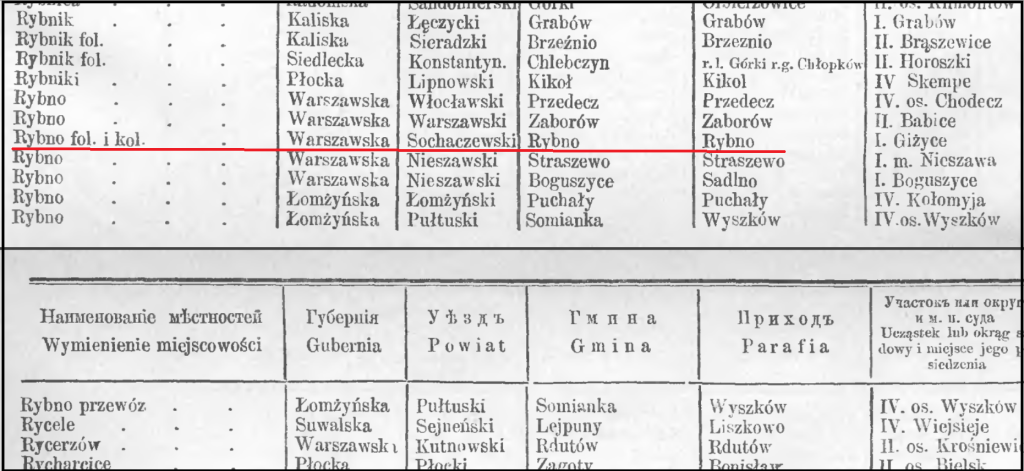
Grandma’s father, Jan/John Zazycki/Zarzycki, was born in 1866 in the village of Bronisławy in Sochaczew County. John died in North Tonawanda, New York, but his parents both died in Poland. His father, Ignacy Zarzycki, died on 8 August 1901 in Bronisławy—a village which belongs to the parish in Rybno. Ignacy was survived by his wife, Antonina (née Naciążek), who died on 14 May 1915 in the Ochota district of Warsaw. She was probably living with her son, Karol, at the time of her death, since he was named as a witness on her death record, and was identified as a resident in Ochota. Antonina’s death was recorded at the parish of St. Stanisław in the Wola district of Warsaw, which suggests that she was buried in the Cmentarz Wolski w Warszawie (Wolska Cemetery in Warsaw), which was established in 1854 and belongs to the parish of St. Stanisław.
Grandma Helen’s mother, Weronika/Veronica (née Grzesiak) Zazycki, was born in the village of Kowalewo-Opactwo in Słupca County in 1876. Her mother, Marianna (née Krawczyńska) Grzesiak, died in the village of Zagórów on 29 May 1904. Curiously, this is contrary to the story I heard from Grandma Helen, that Veronica’s mother was already deceased when Veronica emigrated in 1898, but that’s another story for another day. Grandma Helen had no idea that her father, Józef Grzesiak, ever set foot in the U.S., so she was astonished (and somewhat doubtful) when I discovered a passenger manifest for a family group which included Józef, his daughter, Józefa, and daughter-in-law, Kazimiera Grzesiak. The family arrived in May 1900 and Józef was enumerated in the 1900 census in June, but after that, he disappeared. Oral family history held that Kazimiera was disenchanted with life in the U.S, left her husband, and returned to Poland. I suspect Józef returned as well, since he disappears from U.S. records after that 1900 census, and since his wife was, in fact, still living until 1904.
It’s unclear where Józef went when he returned to Poland, but it is probable that he died in Poland rather than the U.S. His wife’s death record mentioned Józef as a surviving spouse, which implies that he was living in Zagórów when she died in 1904, and that he died between 1904 and 1939 (assuming he lived no more than 100 years). However, no death record was found for him in Zagórów, or in Kowalewo-Opactwo, the parish where he was married and his children were born. The family lived in Warsaw circa 1899, where two of Józef’s children married, and he was named as a witness on the 1899 birth record of his grandson, Marian Cieniewski. Thus far, no death record has been found for Józef in Warsaw, either, but the large number of churches there makes the search difficult. He is not listed in the Buffalo, New York, Death Index, which was searched from 1897 through 1914, so it’s unlikely that he died in Buffalo. Józef Grzesiak’s place and date of death remains a mystery that may one day be solved, as additional indexed records come online.
Grandpa John’s Family
My maternal grandfather, John Zielinski, died on 15 February 2003. My oldest son remembers him pretty well, although he was not quite nine years old when Grandpa died. My other sons have some memories of him, but my daughter knows him only from stories. His pedigree chart is shown in Figure 2.

Grandpa’s father, Joseph/Józef Zieliński, was born in the village of Mistrzewice (Sochaczew County) in 1892, to Stanisław Zieliński and Marianna (née Kalota) Zielińska. Stanisław died 23 December 1915 in Mistrzewice, a village which once had its own parish church, but which was reassigned to the parish in Młodzieszyn in 1898. I suppose, but do not know with certainty, that Stanisław would have been buried in the old cemetery in Mistrzewice, rather than the cemetery in Młodzieszyn. Both cemeteries are still in use today, but searching burials online (for example, at Mogiły (Graves) does not provide much insight into use of the cemeteries during the early 20th century, since most of the graves from that era have new occupants by now.
Marianna Zielińska died 4 April 1936 while living in the village of Budy Stare with her sister. I wrote about her difficult history here. She was the most recent ancestor to die while still living in Poland, and Grandpa John met her when, as a small boy, he returned to Poland with his parents in 1921 for a visit. That visit was precipitated by the death of Grandpa John’s uncle, Władysław Zieliński, who died on 23 March 1921 at the age of 23, leaving his elderly mother, Marianna, as the sole survivor of the family in Poland.
It’s not clear why Marianna did not emigrate when her son, Joseph, returned to the U.S. with his family. They were already settled in North Tonawanda, and enjoying a good life there. But for whatever reason, she chose to remain in Poland, presumably giving up the family farm that Grandpa remembered. I have yet to discover the location of that farm, or documents pertaining to its sale.
Marianna Zielińska had three sisters whom I have been able to identify to date: Barbara, who married Józef Mikołajewski; Józefa, who married Roch Sikora; and Katarzyna, who married Wojciech Wilczek. Marianna outlived both Barbara and Józefa, which suggests that she was living with Katarzyna Wilczek at the time of her death—a conclusion which is supported by the fact that Wojciech and Katarzyna lived in Budy Stare, the village in which Marianna died. Since the village of Budy Stare belongs to the parish in Młodzieszyn, it’s likely that Marianna Zielińska was laid to rest in the that cemetery—perhaps in a grave that is currently occupied by more recent generations of the Wilczek family.
Grandpa John’s mother, Genowefa/Genevieve (née Klaus) Zielinski, was born in Buffalo in 1898, to parents who were Polish immigrants from the Galicia region, in villages that are located in southeastern Poland today. Grandma Genevieve’s mother was Marianna/Mary (née Łącka) Klaus, who was born in the village of Kołaczyce, in the foothills of the Carpathian Mountains. She emigrated in 1884 with her father, Jakub Łącki, and brothers, Jan and Józef, after the death of her mother, Anna, in 1879.
More research is needed to determine Jakub’s date and place of death, since he disappears from indexed records subsequent to his passenger manifest. Since his daughter, Mary, was married in Buffalo, New York, in 1891, he may have died there. However, the family had ties to the Polish community in Dunkirk, New York, and Find-A-Grave contains a promising match for Joseph Lacki’s grave in St. Hyacinth Cemetery in Dunkirk. It’s possible that Jakub is buried in that cemetery as well, without a marker. Further research is needed here; however, the situation with his wife is more definitive. Anna (née Ptaszkiewicz) Łącka, Mary’s mother and Jakub’s wife, died on 13 November 1879 in Kołaczyce, and was laid to rest in the parish cemetery. Jakub’s parents, Franciszek Łącki and Magdalena (née Gębczyńska) Łącka, were buried in that cemetery as well, after their respective deaths on 12 December 1847 and 17 January 1848.
Grandpa John’s mother, Grandma Genevieve (née Klaus) Zielinski, was the daughter of Andrzej/Andrew Klaus, who was born in the village of Maniów in Dąbrowa county, a village which lies just south of the Wisła/Vistula River, along the modern-day border between the Małopolskie Voivodeship and the Świętokrzyskie Voivodeship. Andrew immigrated to the U.S. in 1889, proceeding first to Plymouth, Pennsylvania, according to his passenger manifest, before moving on to Buffalo, where he married Mary Łącka in 1891. His parents were Jakub and Franciszka (née Liguz) Klaus, whose dates and places of death are unknown. Prior to 1981, the village of Maniów belonged to the parish in Szczucin, so they were presumably buried in the parish cemetery there.
And Now, a Map
When it comes to telling family history stories, my husband gave me another piece of sound advice: keep it short, or people’s eyes will start to glaze over. I’m pretty sure that by now, only die-hard genealogists are still reading this, given its length. So, for the sake of my children in Poland, for whom it was also intended, I’ve created the “TL;DR” version. (That’s “too long; didn’t read,” for those of you who aren’t keeping current with your internet acronyms.) Here is a map, showing each of these ancestral burial places.
In contrast to the situation in my family, five of my husband’s Polish immigrant great-grandparents came to the U.S. with their parents. So, it takes a little longer to dig back to the last generation buried in Poland. I’ll discuss them in my next post. As for my kids, I love you, and I hope you’re having a wonderful time in the land of your ancestors!
© Julie Roberts Szczepankiewicz 2022














































{kind=link}